01
談合作:把最好的估算引擎,
帶來最有價值的數據
Frank:
現在在歷史上發揮著重要的作用。對于我們來說,就能帶給數據和小型企業的關系。我們還要啟用這項技術,以及讓整個服務堆棧來有效地使用它。我不想使用「天作之合」來比喻,然而對于一個門外漢,是一個挺好的機會,踏入到這扇機會的正門里。
黃仁勛:
我們是,而不是對手。我們要把世界上最好的估算引擎帶到世界上最有價值的數據。回憶過去,我早已工作了很長時間,而且還沒有這么老。Frank,你更老一些(笑)。
近期,因為眾所周知的成因,數據是很大的,數據是寶貴的。它應當是安全的。聯通數據很困難,數據的引力真實存在。因而,對我們來說,把我們的估算引擎帶到上要容易得多。我們的伙伴關系是加快,但它只是關于將人工智能帶到。
最核心的是,數據+人工智能算法+估算引擎的組合,我們的伙伴關系將所有這三件事結合在一起。令人無法置信的有價值的數據,令人無法置信的偉大的人工智能,令人無法置信的偉大的估算引擎。
我們可以一起做的事情,是幫助顧客使用它們的專有數據,并用它來撰寫AI應用程序。你曉得,這兒的重大突破是,你第一次可以開發一個小型語言模型。你把它放到你的數據后面,于是你與你的數據談話,如同你與一個人談話一樣,而這種數據將被提升到一個小型語言模型中。
小型語言模型加知識庫的組合等于一個人工智能應用。這一點很簡略,一個小型的語言模型將任何數據知識庫弄成一個應用程序。
想想人們所寫的一切驚人的應用程序。它的核心仍然是一些有價值的數據。今天你有一個查詢引擎通用查詢引擎在上面,它超級智能,你可以讓它回應你,但你也可以把它連結到一個代理,這是和向量數據庫帶給的突破。將數據和大語言模型疊加的突破性的東西正在四處發生,每位人都想做。而Frank和我將幫助你們做到這一點。
02
硬件3.0:推行AI應用,
解決一個特定問題
主持人:
作為投資者來看這些變化,硬件1.0是十分確定的代碼,由安裝工程師根據功能寫下來;硬件2.0是用仔細搜集的標記的訓練數據優化一個血管網路。
大家在幫助人們拉動硬件3.0,這套基礎模型原本有令人無法置信的能力,但他們依然須要與企業數據和自定義數據集合作。也是針對他們去開發這些應用程序要實惠得多。
對于這些深入關注這個領域的人來說有一個問題,基礎模型是十分泛化,它可以做所有事情嗎?為何我們還要自定義模型和企業數據呢?
Frank:
因此我們有特別泛化的模型,可以寫詩,處理《了不起的蓋茨比》的做摘要,做英語問題。
然而在商業中,我們不須要很多,我們還要的是一個,在一個特別窄小,而且十分復雜的數據集上斬獲非凡的洞見。
我們還要了解商業方式和商業動態。那樣的估算上不須要這么高昂,由于一個模型并不須要在一百萬件事情上接受訓練,只須要曉得十分少的、但很深入的主題。
舉個實例。我是的監事會成員,我們一個大顧客,像和所有其他企業常面臨的問題是,它們不斷提高營銷成本,來了一個顧客,顧客下了一個訂單,顧客要么不回去,要么90天后回去,這十分不穩定。它們把這稱為流失顧客。
這是復雜問題的剖析,由于顧客不回去的成因或許有好多。人們想找到這種問題的答案,它在數據中,不在通常的互聯網中,并且可以通過人工智能找進去。這就是或許形成很大價值的反例。
主持人:
這種模型應當怎樣與企業數據互動?
黃仁勛:
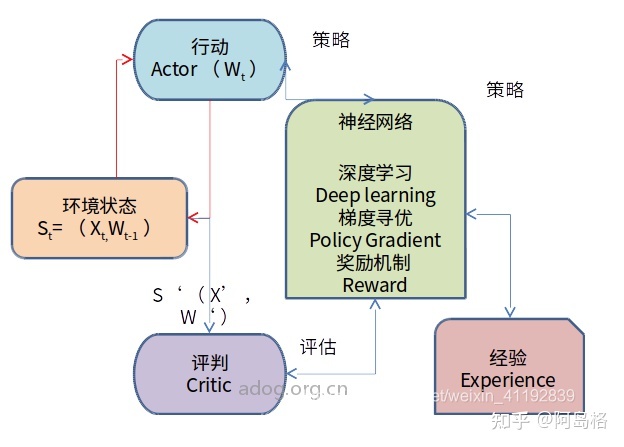
我們的戰略和產品是各類規格、最先進的預訓練模型,有時你還要爭創一個特別大的預訓練模型,從而它可以形成,來教更小的模型。
而較小的模型幾乎可以在任何設備運行,雖然推遲十分低。因此它的泛化能力并不高,zeroshot(零樣本學習)能力或許更有限。
然而,你或許有幾種不同類別不同大小的模型2023搜索引擎營銷的定義,但在每一種狀況下,你應當做監督的微調,你應當做RLHF(人類反饋的加強學習),從而它與你的目標和原則保持一致,你還要用矢量數據庫之類的東西來提高它,因此所有那些都匯集在一個平臺上。我們有技能、知識和基本平臺,幫助她們爭創自己的人工智能,于是將其與中的數據連結上去。
目前,每位企業顧客的目標不應當是探討我怎么構建一個小型的語言模型,它們的目標應當是,我怎么構建一個人工智能應用程序來解決特定的問題?那種應用或許須要17個問題來做,最終得出正確的答案。之后你或許會說,我想寫一個程序,它或許是一個SQL程序,或許是一個程序,那樣我就可以在未來自動做這個。
你還是要引導這個人工智能,讓他最終能給你正確的答案。但在那以后,你可以爭創一個應用程序,可以作為一個代理(Agent)24/7不間斷地運行,尋求相關狀況,并提早向你匯報。因此我們的工作就是幫助顧客推行這種人工智能的應用,這種應用是有安全圍欄的、具體的、定制的。
最終,我們在未來都將成為智能制造商,其實雇傭職員,但我們將爭創一大堆代理,他們可以用LangChain類似的東西來爭創,連結模型、知識庫、其他API,在云中布署,并將其連結到所有的數據。
你可以規模化地操作某些AI,并不斷地加強這種AI。因而,我們每位人都將制造AI、運行AI車間。我們將把基礎設施置于的數據庫,顧客可以在哪里使用它們的數據,訓練和開發它們的模型,操作它們的AI,所以,將是你的數據儲存庫和中行。
有了自己的數據鐵礦,所有人都將在上運行AI車間。這是目標。
03
「核彈」雖貴,
直接用模型相當于「打1折」
黃仁勛:
我們在構建了有五個AI車間,其中四個是世界前500名的超級計算機,另一個正在上線。我們使用這種超級計算機來做預訓練模型。因而,當你在中使用我們的NemoAI基礎服務時,你將得到一個最先進的預訓練模型,早已有幾千萬美金的成本投入其中,更不用說研制投入了。因此它是預先訓練好的。
之后有一大堆其他的模型緊扣著它,這種模型適于微調、RLHF。所有此類模型的訓練費用都要高得多。
然而,如今你早已將預訓練模型適應于你的功能,適應于你的圍欄,優化你希望它具備的技能或功能類別,用你的數據提高。因而,這將是一個更具費用效益的方式。
更重要的是,在幾天內,而不是幾個月。你可以在開發與你的數據連結的人工智能應用程序。
你應當才能在未來迅速確立人工智能應用程序。
由于我們今天看見它正在實時發生。早已有一些應用能否讓你和數據聊天,例如。
主持人:
是的,在硬件3.0時代,95%的輪訓成本早已由他人承當了。
黃仁勛:
(笑)是的,95%的折扣,我沒法想像一個更好的交易。
主持人:
這是真正的動力,作為投資人,我看見在剖析、自動化、法律等領域的特別年青的公司,它們的應用已然在六個月或更短的時間內實現了真正的商業價值。其中一部份成因是它們從這種預先訓練好的模型開始,這對企業來說是一個很大的機會。
黃仁勛:
每家公司還會有數百個,并且1000個人工智能應用程序,也是與你公司的各類數據相通。因此,我們所有人都應當擅于建立這種東西。
04
其實是數據找業務,
目前是業務找數據
主持人:
我經常從大企業參與者看到的一個問題是,我們應當去投資人工智能,我們還要一個新的堆棧(Stack)嗎?應當怎樣考慮與我們現有的數據堆棧相通?
Frank:
我覺得它在不斷發展。模型們正逐步顯得更別致、安全、更好地被管理。因此,我們沒有一個真正明晰的觀點,這就是每位人就會使用的參考構架?有些人將有一些中央服務的設置。谷歌有Azure中的人工智能版本,他們的這些顧客正在與Azure進行互動。
但我們不清楚哪些模型將主導,我們覺得市場將在使用難易、成本這種事上進行自我排序。目前只是是開始,不是最終的狀態。
安全部委也會參與過來,關于版權的問題會被革新。今天我們對技術很著迷,現實中的問題也會被同時處理。
黃仁勛:
我們目前正經歷60年來第一次根本性的估算平臺轉型。假如你剛才讀了IBM360的新聞稿,你會看到關于中央處理單元、IO子系統、DMA控制器、虛擬顯存、多任務、可擴充估算往前和向前端兼容,而這種概念,實際都是1964年的東西2023搜索引擎營銷的定義,而這種概念幫助我們在過去六七年來,不斷進行CPU擴充。
那樣的擴充早已進行了60年了,但這早已走到了盡頭。今天你們都明白,我們沒法再擴充CPU了,忽然之間,硬件變化了。硬件的撰寫方法,硬件的操作模式,以及硬件能做的事情都與先前有巨大的不同。我們稱之前的硬件為硬件2.0。目前是硬件3.0。
事實就是,估算早已從根本上改變了。我們聽到兩個基本的動力在同時發生,這只是為何今天事情正在發生猛烈反彈。
一方面,你不能再不斷地訂購CPU。假如你今年再賣一大堆CPU,你的估算吞吐量將不會提高。由于CPU擴充的終點早已到來了。你會多花一大堆錢,你不會得到更多的吞吐量。為此,答案是你應當去加快(英偉達加快估算平臺)。圖靈獎榮獲者提到了加快,英偉達引領了加快,加快估算目前早已到來。
另一方面是,計算機的整個操作系統發生了深刻的改變。我們有一個叫AI的層,而其中的數據處理、訓練、推理布署,整個目前早已整合到或正在整合到中,然而,從開始數據處理,經常到最后的大模型布署,整個背后的估算引擎都被加快了。我們將賦能,在這兒你將才能做得更多,但是你將還能用更少的資源做到更多。
假如你去任何一個云,你會看見GPU是其中最高昂的估算實體。并且,假如你把一個工作負載放到旁邊,你會發覺我們做得十分快。就好似你得到了一個95%的折扣。我們是最高昂的估算實體,但我們是最具費用效益的TCO。
因此,假如你的工作是運行工作負載,或許是訓練小型語言模型,或許是微調小型語言模型,假若你想這么做,一定要進行加快。
加快每一個工作負載,這就是整個棧的重構。處理器因而發生變化,操作系統因而不同,大的語言模型是不同的,你寫AI應用程序的形式是不同的。
未來,我們都要寫應用。我們都要把我們的和我們的上下文,和少數幾個命令連結上去,連結到大語言模型和自己的數據庫或則公司的數據庫中,開發自己的應用程序。每位人都將成為一個應用程序的開發者。
主持人:
但不變的是,它依然是你的數據。你一直還要對它進行微調。
Frank:
其實我們都認為更快的總是更貴的。實際上忽然之間,更快的是更實惠的,這是一種反直覺的東西。因而,有時人們想提高供應,以為那樣更實惠,結果卻更貴。
另一個與之前矛盾的是,其實都是數據去找業務(datagoingtowork),而如今,業務去找數據(workgoingtodata)。過去的六七年,或則更多年,我們仍然在讓數據去找業務,這引起了大規模的信息荒島。而假如你想擁有一個AI車間,用之前的做法將是十分困難的。我們應當把估算帶到數據所在的地方。我覺得我們目前正在做的就是正確的方法。
05
企業怎么榮獲
最快和最大的價值
Frank:
最快和榮獲最大價值或許是兩個很不一樣的問題。
最快的話,你很快就能看見,數據庫各處都上線了人工智能提升的搜索方法,由于這是最容易提高的功能。目前,并且一個文盲都能從數據中獲取有價值的信息,這真十分不可思議,這是終極的交互民主化。搜索功能極大提高,你就向主界面提一個問題,他們可以把這種問題帶到數據自己進行查詢。這是掛在低處的果實,最容易的,我們覺得這是階段一。
接下去,我們就開始真正關注真正的瓶頸,就是專有的企業數據,混和結構化的、非結構化的,所有那些,我們怎么調動這種數據?
我旁邊早已提及了toC企業面臨的流失率問題,供應鏈管理方面的問題。當供應鏈非常復雜的時侯,假如有一個丑聞發生了,我們怎么再次調整一個供應鏈,使其運轉?我今天該如何做?供應鏈是由這些不同的實體組成的,不是單一的企業。歷史上,這是一個未曾被估算解決過的問題。供應鏈管理從來沒有產生過一個平臺,它幾乎是一個電子電郵,電子表格產生的機制,不僅一些小的例外。因而,這是十分令人激動的。
或則我們可以再次估算小型的呼叫中心的投資,優化零售的定價,像我說的,這是一個大企業的CEO們經常期盼的再次定義商業機制,是真正的潛力。
06
對企業的建議:
黃仁勛:
我會問自己,第一,哪些是我惟一最有價值的數據庫?第二件事,我會問自己,假如我有一個超級、超級、超級聰慧的人,而企業的一切數據都經過那種超級智能,我會問哪個人哪些?
按照每位人的公司,這是不同的。Frank的公司顧客數據庫極其重要,由于他有太多顧客。而我自己的公司,沒有這么多顧客,但對我的公司而言,我的供應鏈超級復雜,但是我的設計數據庫也超級復雜。
對來說,沒有人工智能我們早已未能建造出GPU。由于我們的安裝工程師都不或許像AI這樣,為我們進行大量的迭代和探求。因而,當我們提出人工智能的時侯,第一個應用在我們自己的公司。并且,因此(英偉達超算產品)不或許沒有人工智能的設計。
我們也會將我們自己的AI應適于我們自己的數據中。我們的錯誤數據庫就是一個完美的應用場景。假如你看一下AI的代碼量,我們有幾百個硬件包,結合在一起,支持一個應用程序才能跑上去。我們今天正在努力的一些事情,就是怎樣使用AI去弄清楚怎樣給它打安全補丁,怎么最好地維護它,那樣我們就可以毋須干擾整個下層應用層的同時,還能向前端兼容。
這都是AI才能為你提供答案的。我們可以用一個大語言模型去回答此類問題,為我們找到答案,或則向我們揭露一些問題,于是安裝工程師就可以再將其修好。或則AI可以推薦一個修補方式,人類安裝工程師再去確認這是不是一個好的修補方式。
我認為不是所有人都認識到了她們每天都在處理的數據旁邊,然而蘊涵著多少智能、洞見和影響力沒有被開掘。這就是為何我們所有人都要參與過來,幫助帶給那樣的未來。
目前,你儲存在數據庫房的數據,第一次可以被連結進人工智能車間。你將才能生產信息情報,這是世界上最有價值的商品。你坐在一個自然資源的銅礦上——你公司的專有數據,而我們今天把它連結到一個人工智能引擎上,另一端每次直接形成信息情報,以無法置信的情報量從另一端涌出,并且在你吃飯時也在源源不斷地產出。這是有史以來最好的事情。
 名師輔導
環球網校
建工網校
會計網校
新東方
醫學教育
中小學學歷
名師輔導
環球網校
建工網校
會計網校
新東方
醫學教育
中小學學歷





 免費試聽
免費試聽

 今日
今日








 您現在的位置:
您現在的位置:









