
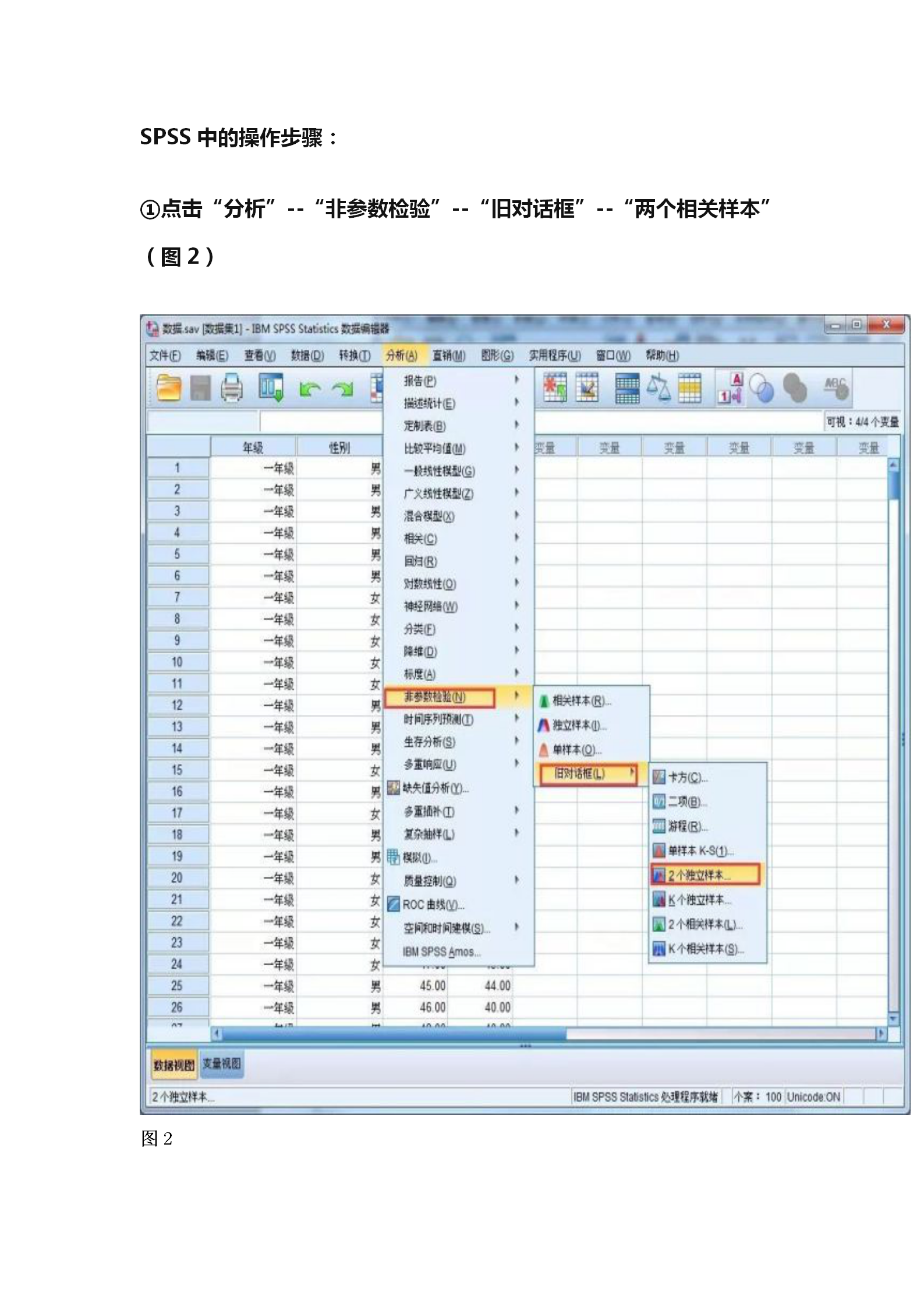
 您現(xiàn)在的位置:網(wǎng)校頭條 > 二級建造師 > 相關(guān)性模型 之 皮爾遜相關(guān)系數(shù)與斯皮爾曼相關(guān)系數(shù)
您現(xiàn)在的位置:網(wǎng)校頭條 > 二級建造師 > 相關(guān)性模型 之 皮爾遜相關(guān)系數(shù)與斯皮爾曼相關(guān)系數(shù) 皮爾遜相關(guān)系數(shù)和斯皮爾曼等級相關(guān)系數(shù)。它們可拿來評判兩個變量之間的相關(guān)性的大小,按照數(shù)據(jù)滿足的不同條件,我們要選擇不同的相關(guān)系數(shù)進行估算和剖析(建模論文中最容易用錯的技巧)。
一、基本概念
總體——所要考察對象的全部個體稱作總體.
我們總是希望得到總體數(shù)據(jù)的一些特點(比如均值殘差等)
樣本——從總體中所抽取的一部份個體稱作總體的一個樣本
估算這種抽取的樣本的統(tǒng)計量來恐怕總體的統(tǒng)計量:
比如使用樣本均值、樣本標準差來恐怕總體的均值(平均水平)和總體的標準差(偏離程度)
假定檢驗:參閱《概率論與數(shù)理統(tǒng)計》第八章
二、皮爾遜相關(guān)系數(shù)
就是機率論學的相關(guān)系數(shù)。通常我們覺得不加前綴說明的相關(guān)系數(shù)都是皮爾遜相關(guān)系數(shù)
首先我們要理解協(xié)殘差
關(guān)于協(xié)殘差:假如X、Y(相對于均值)變化方向相同則乘積為正,反之為負
注:協(xié)殘差的大小和兩個變量的量綱有關(guān),因而不適宜做比較。
所以我們引入皮爾遜相關(guān)系數(shù)剔除了量綱的影響,正式X和Y標準化后的協(xié)殘差
(1)總體皮爾遜相關(guān)系數(shù)
(2)樣本皮爾遜相關(guān)系數(shù)
一些誤區(qū)
以上的相關(guān)系數(shù)只是拿來來評判兩個變量線性相關(guān)程度的指標;即我們必須先確認這兩個變量是線性相關(guān)的,之后這個相關(guān)系數(shù)能夠告訴你他倆相關(guān)程度怎樣(先畫散點圖)
eg.方式上必須大致滿足Y=a*X+b
比如下邊幾個錯誤示例
總結(jié):
假如兩個變量本身就是線性的關(guān)系,這么皮爾遜相關(guān)系數(shù)絕對值大的就是相關(guān)性強,小的就是相關(guān)性弱;在不確定兩個變量是哪些關(guān)系的情況下,雖然算出皮爾遜相關(guān)系數(shù),發(fā)覺很大,也不能說明那兩個變量線性相關(guān),甚至不能說她們相關(guān),我們一定要畫出散點圖來看才行。相關(guān)系數(shù)的明顯性
通常相關(guān)系數(shù)大小與相關(guān)性的參照如上。**并且!!!**上表所定的標準從某種意義上說是輕率的和不嚴格的。對相關(guān)系數(shù)的解釋是依賴于具體的應用背景和目的的。
所以,比起相關(guān)系數(shù)的大小,我們常常更關(guān)注的是明顯性。(假定檢驗)
用勾畫散點圖觀察是否為線性(SPSS更為便捷)對數(shù)據(jù)進行描述性統(tǒng)計(每位指標的最小值、最大值、均值、中位數(shù)值、偏度、峰度、標準差等)估算相關(guān)系數(shù)矩陣()。可以對其進行數(shù)據(jù)可視化處理(Excel)對皮爾遜相關(guān)系數(shù)進行假定檢驗:
(1)查表法
注:
在數(shù)理統(tǒng)計中,第二步的原假定和備擇假定中的應當改為,其中為未知的總體相關(guān)系數(shù),實際上我們關(guān)心的是總體的統(tǒng)計特點。(意思喃大約就是如此個意思,考量我就看不懂了)
t分布表:/e94a.html
(2)p值判別法
這些方式要簡單一點
補充:0.5、0.5*、0.5**、0.5***的涵義(明顯性標記)
通常我們默認的置信水平是95%(即明顯性水平是5%)
估算各列之間的相關(guān)系數(shù)以及p值代碼
[R,P] = corrcoef(Test)
%R返回的是相關(guān)系數(shù)表,P返回的是對應于每個相關(guān)系數(shù)的p值
皮爾遜相關(guān)系數(shù)假定檢驗的條件
第一、實驗數(shù)據(jù)一般假定是成對的來自于正態(tài)分布的總體。由于我們在求皮爾遜相關(guān)性系數(shù)之后,一般都會用t檢驗之類的方式來進行皮爾遜相關(guān)性系數(shù)檢驗,而t檢驗是基于數(shù)據(jù)呈正態(tài)分布的假定的。
第二、實驗數(shù)據(jù)之間的差別不能太大。皮爾遜相關(guān)性系數(shù)受異常值的影響比較大。
第三、每組樣本之間是獨立抽樣的。構(gòu)造t統(tǒng)計量時須要用到
檢驗樣本是否符合正態(tài)分布
(1)JB檢驗(雅克‐貝拉檢驗):大樣本n>30
峰度和偏度:
峰度就是樣本的三階矩,偏度是四階矩。偏度左正右負,峰度越大越尖
x = normrnd(2,3,100,1);
% 生成100*1的隨機向量,每個元素是均值為2,標準差為3的正態(tài)分布
skewness(x) %偏度
kurtosis(x) %峰度
在的JB檢驗函數(shù)
[h,p] = jbtest(x,alpha)
%當輸出h等于1時,表示拒絕原假設(shè);h等于0則代表不能拒絕原假設(shè)。
%alpha就是顯著性水平,一般取0.05,此時置信水平為1‐0.05=0.95
%x就是我們要檢驗的隨機變量,注意這里的x只能是向量。
(2)-wilk檢驗(夏皮洛‐威爾克檢驗):小樣本:3 這個通過SPSS較為便捷 得到的這個表只用看最后一列就好啦 這樣檢驗的話還可以得到一些QQ圖 (3)Q-Q圖 在統(tǒng)計學中,Q‐Q圖(Q代表分位數(shù))是一種通過比較兩個機率分布的分位數(shù)對這兩個機率分布進行比較的機率圖方式。 首先選取分位數(shù)的對應機率區(qū)間集合,在此機率區(qū)間上,點(x,y)對應于第一個分布的一個分位數(shù)x和第二個分布在和x相同機率區(qū)間上相同的分位數(shù)。 這兒,我們選擇正態(tài)分布和要檢驗的隨機變量,并對其作出QQ圖,可想而知,假如要檢驗的隨機變量是正態(tài)分布相關(guān)系數(shù)公式,這么QQ圖就是一條直線。要借助Q‐Q圖鑒定樣本數(shù)據(jù)是否近似于正態(tài)分布,只需看Q‐Q圖上的點是否近似地在一條直線附近。(要求數(shù)據(jù)量十分大!!!)qqplot(Test(:,1))
三、斯皮爾曼相關(guān)系數(shù)
注:另一種定義:等級之間的皮爾遜相關(guān)系數(shù)
這個是可以證明的相關(guān)系數(shù)公式,并且實際應用中結(jié)果可能與第一種定義有所不同(由于這個規(guī)定:假如有的數(shù)值相同,則將它們所在的位置取算術(shù)平均)。假如數(shù)據(jù)沒有相同的則理論上與第一種定義結(jié)果相等。
斯皮爾曼相關(guān)系數(shù)的復句:
(1)corr(X , Y , 'type' , 'Spearman')
%這里的X和Y必須是列向量
(2)corr(X , 'type' , 'Spearman')
%這時計算X矩陣各列之間的斯皮爾曼相關(guān)系數(shù)
%matlab用的是第二種定義
斯皮爾曼相關(guān)系數(shù)的假定檢驗
(1)小樣本(<):直接查臨界值表
臨界值表
(2)大樣本情況(n>30):P值法
% 直接給出相關(guān)系數(shù)和p值
[R,P]=corr(Test, 'type' , 'Spearman')
四、兩種相關(guān)系數(shù)的比較
皮爾遜相關(guān)系數(shù):
斯皮爾曼相關(guān)系數(shù):
斯皮爾曼相關(guān)系數(shù)和皮爾遜相關(guān)系數(shù)選擇:
1.連續(xù)數(shù)據(jù),正態(tài)分布,線性關(guān)系,用相關(guān)系數(shù)是最恰當,其實用相關(guān)系數(shù)也可以,就是效率沒有相關(guān)系數(shù)高。
2.上述任一條件不滿足,就用相關(guān)系數(shù),不能用相關(guān)系數(shù)。
3.兩個定序數(shù)據(jù)之間也用相關(guān)系數(shù),不能用相關(guān)系數(shù)。
注:(1)定序數(shù)據(jù)是指僅僅反映觀測對象等級、順序關(guān)系的數(shù)據(jù),是由定序尺度計量產(chǎn)生的,表現(xiàn)為類別,可以進行排序,屬于品質(zhì)數(shù)據(jù)。
eg.優(yōu)良差用123表示,加減乘除沒有意義。定序數(shù)據(jù)最重要的意義代表了一組數(shù)據(jù)中的某種邏輯次序
(2)斯皮爾曼相關(guān)系數(shù)的適用條件比皮爾遜相關(guān)系數(shù)要廣,只要數(shù)據(jù)滿足單調(diào)關(guān)系(比如線性函數(shù)、指數(shù)函數(shù)、對數(shù)函數(shù)等)就才能使用
另:對數(shù)據(jù)的可視化(相關(guān)系數(shù)矩陣)
 名師輔導
環(huán)球網(wǎng)校
建工網(wǎng)校
會計網(wǎng)校
新東方
醫(yī)學教育
中小學學歷
名師輔導
環(huán)球網(wǎng)校
建工網(wǎng)校
會計網(wǎng)校
新東方
醫(yī)學教育
中小學學歷




 免費試聽
免費試聽

 今日
今日


















